紀錄開發上常遇到的問題,避免重複踩坑。
各種進制轉換成 10 進制 1 2 3 4 val = bytes .fromhex('00FF' ) print (int .from_bytes(val, byteorder='big' )) print (int .from_bytes(val, byteorder='little' ))
讀取 yaml 檔 需安裝 pyyaml 套件
1 2 3 4 import yamlwith open ('config.yml' , encoding='UTF-8' ) as stream: configs = yaml.safe_load(stream)
輸出 yaml 換行格式 1 2 3 4 5 6 7 def repr_str (dumper: yaml.SafeDumper, data ): if '\n' in data: return dumper.represent_scalar('tag:yaml.org,2002:str' , data, style='|' ) return dumper.represent_str(data) yaml.add_representer(str , repr_str, Dumper=yaml.SafeDumper) print (yaml.safe_dump(foo))
讀取 zip 檔內的文字檔內容 1 2 3 4 5 import zipfilewith zipfile.ZipFile('path/to/zip_file' , 'r' ) as zip_ref: linesb = zip_ref.open (zip_ref.namelist()[0 ]).readlines() print ('' .join([lineb.decode('UTF-8' ) for lineb in linesb]))
讀取加密 zip 檔內的文字檔內容 需安裝 pyzipper 套件
1 2 3 4 5 6 7 8 9 import pyzipperimport zlibwith pyzipper.AESZipFile(output_path) as zip_ref: try : linesb = zip_ref.open (zip_ref.namelist()[0 ], pwd='your/password' .encode()).readlines() print ('' .join([lineb.decode('UTF-8' ) for lineb in linesb])) except zlib.error as e: print ('密碼錯誤' , e)
解壓縮 rar 檔 需安裝 unrar 套件,並新增環境變數 UNRAR_LIB_PATH = C:\Program Files (x86)\UnrarDLL\x64\UnRAR64.dll
1 2 3 4 from unrar import rarfilewith rarfile.RarFile('path/to/rar_file' ) as rar_ref: rar_ref.extract(rar_ref.namelist()[0 ], 'unrar/to/path' )
開啟資料夾 1 2 3 4 5 6 7 8 import subprocessdef open_folder (path ): """開啟資料夾""" if platform.system() == 'Darwin' : subprocess.call(['open' , path]) else : subprocess.call(['start' , path], shell=True )
取得日期 1 2 3 4 5 6 7 8 9 10 11 12 13 import timefrom datetime import datetime, timedeltatoday = time.strftime('%Y/%m/%d %H:%M:%S' ) print (today)yesterday = datetime.today() + timedelta(days=-1 ) print (yesterday.strftime('%Y%m%d' ))someday = datetime.fromtimestamp(1721095603 ) print (someday.strftime('%Y%m%d' ))today = datetime.today() twenty_years_old = today.replace(year=today.year - 20 )
取得照片拍攝日期 參考 https://steam.oxxostudio.tw/category/python/example/image-exif.html
1 2 3 4 from PIL import Imagewith Image.open (path) as im: im.getexif().get_ifd(0x8769 ).get(36867 )
NAS 連線並取檔 需安裝 pysmb 套件
1 2 3 4 5 6 7 8 9 from smb.SMBConnection import SMBConnectionconn = SMBConnection('user' , 'pwd' , '' , '' , domain='your_domain' ) if not conn.connect('ip' , port=445 , timeout=10 ): print ('連線失敗' ) return with open ('path/to/output_file' , 'wb' ) as output_file: conn.retrieveFile('share_folder' , 'path/to/file' , output_file) conn.close()
支援 SMB2/3 需安裝 smbprotocol 套件
1 pipenv install smbprotocol
參考 https://github.com/jborean93/smbprotocol/blob/master/examples/high-level/file-management.py
1 2 3 4 5 6 7 from smbclient import register_session, open_fileregister_session('ip' , username='user' , password='pwd' ) with open ('path/to/output_file' , 'wb' ) as output_file: with open_file(r"\\ip\path\to\file" , mode="rb" ) as fd: output_file.write(fd.read())
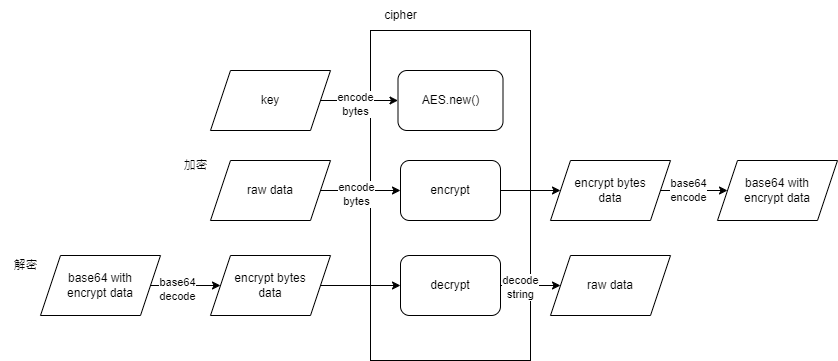
AES 加解密 需安裝 pycryptodome 套件
1 pipenv install pycryptodome
通常拿到的 key 是用 Hex 表示的字串,要用 bytes.fromhex(key)轉換成 bytes。
加密後的結果為 bytes,無法直接編碼成字串,所以中間會先轉成 Base64。因此解密時,資料已經過 Base64 編碼,需 Base64 解碼後才丟進 AES 解密。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import base64from Crypto.Cipher import AESfrom Crypto.Util.Padding import pad, unpadaes_key = 'C6DFE59F58353AEF73549370CD98F0A9547EF16C74974C16520F0C868ECB78EC' data = 'Hello world' def aes_encrypt (key, text ): """AES加密""" cipher = AES.new(bytes .fromhex(key), AES.MODE_ECB) result = cipher.encrypt(pad(text.encode(), AES.block_size)) result_b64 = base64.b64encode(result) result_str = result_b64.decode() return result_str def aes_decrypt (key, text ): """AES解密""" text_b64 = text.encode() text_b = base64.b64decode(text_b64) cipher = AES.new(bytes .fromhex(key), AES.MODE_ECB) result = unpad(cipher.decrypt(text_b), AES.block_size) result_str = result.decode() return result_str if __name__ == '__main__' : text = aes_encrypt(aes_key, data) print (text) data = aes_decrypt(aes_key, text) print (data)
輸出結果
1 2 LE1WdHzcoXb7ul3S9b5otQ== Hello world
Requests 紀錄 API 請求和回應 參考https://stackoverflow.com/questions/16337511/log-all-requests-from-the-python-requests-module
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import loggingfrom http.client import HTTPConnectiondef debug_requests_on (): '''Switches on logging of the requests module.''' HTTPConnection.debuglevel = 1 logging.basicConfig() logging.getLogger().setLevel(logging.DEBUG) requests_log = logging.getLogger("requests.packages.urllib3" ) requests_log.setLevel(logging.DEBUG) requests_log.propagate = True def debug_requests_off (): '''Switches off logging of the requests module, might be some side-effects''' HTTPConnection.debuglevel = 0 root_logger = logging.getLogger() root_logger.setLevel(logging.WARNING) root_logger.handlers = [] requests_log = logging.getLogger("requests.packages.urllib3" ) requests_log.setLevel(logging.WARNING) requests_log.propagate = False
requests_html 出現 SSLCertVerificationError 第一次執行會有 SSLCertVerificationError 問題
1 2 3 4 5 [W:pyppeteer.chromium_downloader] start chromium download. Download may take a few minutes. Traceback (most recent call last): 略... ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1056)
修正如下,參考https://github.com/miyakogi/pyppeteer/issues/219
1 pip install -U "urllib3<1.25"
os.popen()在 Windows 下出現 UnicodeDecodeError: ‘cp950’ codec can’t decode byte os.popen()是封裝 subprocess.Popen(),並用 io.TextIOWrapper 轉換 bytes 輸出成 str 的結果,而 Windows 下的 cmd 指令預設為 cp950,會造成解析錯誤。
1 2 3 4 5 proc = subprocess.Popen(cmd, shell=True , stdout=subprocess.PIPE, bufsize=buffering) return _wrap_close(io.TextIOWrapper(proc.stdout), proc)
所以針對 Windows 自行實作 popen(),調整如下
1 2 3 4 5 def popen (command ): if platform.system() == 'Darwin' : return os.popen(command) proc = subprocess.Popen(command, stdout=subprocess.PIPE) return io.TextIOWrapper(proc.stdout, encoding='UTF-8' )
如果要讀取的是 bytes 則用 io.BufferedReader
1 2 3 proc = subprocess.Popen(command, stdout=subprocess.PIPE) stream = io.BufferedReader(proc.stdout) print (stream.read())
Flask 保留 json 排序 參考https://stackoverflow.com/questions/54446080/how-to-keep-order-of-sorted-dictionary-passed-to-jsonify-function
1 2 app = Flask(__name__) app.config['JSON_SORT_KEYS' ] = False
依指定長度切割陣列 參考https://www.altcademy.com/blog/how-to-split-a-list-in-python/
1 2 3 4 5 6 7 8 9 def split_list (lst, chunk_size ): return [lst[i:i + chunk_size] for i in range (0 , len (lst), chunk_size)] numbers = [0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] chunk_size = 3 chunks = split_list(numbers, chunk_size) print ("Chunks:" , chunks)
身分證/新舊居留證格式檢驗 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import redef check_pid (value: str ): local_table = {'A' :1 ,'B' :0 ,'C' :9 ,'D' :8 ,'E' :7 ,'F' :6 ,'G' :5 ,'H' :4 ,'I' :9 , 'J' :3 ,'K' :2 ,'L' :2 ,'M' :1 ,'N' :0 ,'O' :8 ,'P' :9 ,'Q' :8 ,'R' :7 , 'S' :6 ,'T' :5 ,'U' :4 ,'V' :3 ,'W' :1 ,'X' :3 ,'Y' :2 ,'Z' :0 } local_table2 = {'A' :0 ,'B' :8 ,'C' :6 ,'D' :4 } if re.match (r'[A-Z]{1}[1-2]{1}[0-9]{8}' , value) or re.match (r'[A-Z]{1}[8-9]{1}[0-9]{8}' , value): check_num = local_table[value[0 ]] for i in range (1 , 9 ): check_num += int (value[i])*(9 -i) check_num += int (value[9 ]) return check_num % 10 == 0 elif re.match (r'[A-Z]{1}[A-D]{1}[0-9]{8}' , value): check_num = local_table[value[0 ]] check_num += local_table2[value[1 ]] for i in range (2 , 9 ): check_num += int (value[i])*(9 -i) check_num += int (value[9 ]) return check_num % 10 == 0 return False
Pandas 讀取 csv 1 2 3 4 5 6 7 8 9 10 11 import pandas as pdimport csvdf = pd.read_csv('path/to/file.csv' ) print (df)with open ('path/to/file.csv' , newline='' , encoding='UTF-8-SIG' ) as csvfile: reader = csv.reader(csvfile) for row in reader: print (row[0 ])
讀取 excel 1 2 3 4 5 6 import pandas as pddf = pd.read_excel('path/to/file.xlsx' , header=0 , sheet_name='Sheet1' , dtype=str ) for index, row in df.iterrows(): print (row['column_name' ])